
Many people have pointed out the irony that venture funds invest in the most cutting edge technology yet still operate with excel, quickbooks, and "gut feel". Given the current awareness of the value of data and the rise of machine learning, is there an opportunity for technology to radically alter the venture landscape like it did for the public markets in the 80s?
At my previous fund, Hone Capital based in Palo Alto, we thought so. We built machine learning models to enhance the GP decision in investing in over 350 early stage technology companies. You can read more about our approach in McKinsey Quarterly.
In this post I want to first look at quantitative approaches in the public markets, how the market structure influenced these strategies and how these don't directly translate to the private markets. Then look at how the private market architecture is changing and how that might present new opportunities for quant strategies in VC.
The Different Goals of Traditional vs. Quant
The goal of traditional investing, put simply, is to find undervalued companies. Traditional investors have always used data (well maybe I shouldn't say always; Benjamin Graham introduced the idea of an "investment policy" rather than speculation and hoped to implant in the reader of his canonical "The Intelligent Investor" a "tendency to measure or quantify.") The traditional investors' data consists of revenue, margins, growth rates, etc.: metrics I call 'primary' to the company.
Perhaps inevitably, the data used by traditional investors is growing. Now the term 'quantamental' is used for those using "alternative data" like satellite images, app download numbers etc. This is still however, using data (albeit new forms of data) to achieve the same goal: identify undervalued businesses.
It's important to note when translating public quant strategies to VC, quant hedge funds don't use data to enhance the traditional goal, but rather they have created an entirely new goal and have profited handsomely to say the least. The quant funds used data to create a completely different goal: find repeatable, short term statistical patterns. In effect, the quant strategies grew out of the "data exhaust" of traditional investing.
Comparing Public and Private Market Structures
“Longer term trading makes algorithms less useful”

Jim Simons, The New Yorker profile
The architecture of public and private markets is very different. Below is an examination of the elements of the public markets that led to the development of the quant strategies that have been so successful. To make the comparison clear with the private markets (since our goal here is to explore opportunities for quant VC) I also list the challenges of translating the public market strategies to the private market.
1. Investment Time Horizon
Public market: Short. The ability to trade within minutes (seconds, microseconds etc.) allows the quant hedge funds to isolate a statistical driver of profit. This is originally how Renaissance Technologies started: they "predicted" the very short term response to a macroeconomic announcement (non-farm payrolls, consumer price index, GDP growth etc) by analyzing a huge (analog) database of how securities responded to those announcements in the past. By trading in and out within minutes, no other exogenous factors influence the security response in that time (theoretically.)
Private market: Very Long. Venture investments have a long time horizon and the investment is extremely illiquid (this is changing now to some extent with companies like EquityZen, SharesPost and Equidate - but even still these are mostly for later stage secondaries and still only offer "trade" windows of months at least.) The long time horizon between opportunities to exit an investment mean that many exogenous, unplanned and unpredictable factors undermine the potential for statistical patterns to provide any alpha. These exogenous factors lead to an exponential decay in the accuracy of any forecast over time.
2. Feature Extraction
Public market: Difficult. Quant hedge funds compete on identifying a "signal" with which to trade. RenTech famously released one signal they had found - fine weather in the morning correlated to upward trend in the stock market in that city. However, the trend wasn't big enough to overcome transaction costs - so they released it publicly. The point here is that the quant hedge funds have an almost unlimited amount of data to mine: intra-second, machine readable, tic-by-tic price movements on thousands of securities and derivatives all over the world.
Private market: Difficult. By definition, private companies keep information private. There are no tic-by-tic data libraries of valuation movements (indeed valuations only move in discrete steps.) There is also a limited historical set of information on startups (changing rapidly thanks to PitchBook, Crunchbase and CBInsights.) This means that if you want to build quant models for the private market you need to get creative (beyond PitchBook, Crunchbase etc.) For example, although it was still for their public quant hedge fund, Winton released a blog post systematically examining a companies proclivity to register their domain name in different countries and whether that could be a signal for the competence of company's technical leadership. Systematic feature extraction seems to be the original direction of Google Ventures when they discussed strategy more publicly at launch back in 2013:
“There are a number of signals you can mine and draw patterns from, including where successful entrepreneurs went to school, the companies they worked for and more”

Graham Spencer and Bill Maris, New York Times, Google Ventures Stresses Science of Deal Not Art of Deal
3. Availability of Data
Public market: Rich. Long historical record of continuous, machine readable and easily accessible data.
Private market: Sparse. Various sources offering incomplete data (missing data; missing founding rounds, conflicting reports etc.) The data is often not easily machine readable: names of funds could be First Round, First Round Capital, FRC, Josh Kopelman, FirstRound.) Extensive data cleaning is required (not to say this doesn't happen at the quant hedge funds, but less is required given the maturity of the data market for quant funds.)
4. Ease of Signal Expression
Public market: Easy. The public markets are continuous and liquid. One only needs to identify a signal and expression of that signal is trivial (assuming liquidity is not an issue which it most certainly is in some high frequency trading scenarios.)
Private market: Hard. Even after the data is acquired, cleaned, made machine readable and a signal is found, the venture investor has to identify a new opportunity that matches that signal and also win access to that deal. Whereas the public markets are liquid and freely accessible, the private markets, again almost by definition, require 'permission based access.'
5. Required Accuracy of Signal:
Public market: Low. The CIO of a $30b+ quant hedge fund once told me that if the signal is >50.1% accurate it is in play. The only way this works if if there are thousands of possible trades using this signal. Invoking the Law of Large Numbers, a 50.1% signal becomes profitable. So the extremely high number of possible trades (given the highly liquid, global, permission-less public market architecture) makes it a lot easier to identify a signal that can be used.
Private market: High. In contrast, a venture fund has to have some concentration in portfolio companies to achieve traditional 3.0x+ ROIC that LPs expect. This translates to a low number of portfolio companies (to build/maintain high ownership.) A low number of "trades" therefore requires a highly accurate signal (much greater than 50% (a false negative in venture is very bad.) One could push back on this however: in trying to develop a benchmark for our ML models, I once asked a Partner at Sequoia what he considers a "high" seed - series A conversion rate. His answer: 50%.) I've explored the mathematical dynamics and efficacy of a larger, index-style VC fund here.
So how do we address these limitations of the private markets? Well the early stage private market architecture itself has been changing.
Changing Private Market Architecture
In an almost Soros-like reflexive loop, the number of deals done and the amount of data on these deals has dramatically increased over time.
Data
The graph below (from PwC Moneytree) shows the number of deals done (line) and amount of capital deployed to 'seed stage' deals from 1Q02 to 1Q18. It shows a 30x increase in the number of seed deals and a 40x increase in capital deployed at seed.
Over that time companies were created to operationalize the data generated from these deals: PitchBook (2007), Crunchbase (2007), CBInsights (2008), AngelList (2010). Over this exact same timeframe, LinkedIn profiles grew from 10 in 2003 at launch to over 500m today (same trend can probably be seen in AngelList, Twitter, ProductHunt profiles.) This increase in the number of deals and data available (on those deals, founders, and other features) means more training data for machine learning models. The amount ad quality of data will only increase.

Liquidity
Liquidity has substantially increased in the early stage private market for three reasons: incredible proliferation of 'micro-VCs', mega-funds (SoftBank et. al.) and new secondary market options. Senior Managing Director at First Republic (and great VC blogger) Samir Kaji recently mentioned in a post they are tracking close to 650 micro-VCs and characteristically offers some insight into how this growth might influence the market architecture going forward.

Given this dispersion of ownership interests in companies among many distinct funds, like Samir I find it very likely that consolidation will occur - and potentially the development of a new market - something I'm calling Synthetic Liquidity. This would be when a fund sells their ownership position prematurely (like at Series A or B) and the buying fund pays the selling fund carry. Obviously the selling fund is forgoing potentially lucrative upside but they are buying quick liquidity. I see AngelList being very well positioned to be the intermediary here.
Shortening the time to realization may make some quant strategies viable (like using ML to forecast 1 - 2 years out rather than 10.) The idea here is that the early stage venture market is in a period of realignment which may introduce opportunity for new quant strategies.
Not much needs to be said here about the other secondary options available, just that they have contributed to the changing landscape of liquidity in the private market: SharesPost (2009), EquityZen (2013) and Equidate (2014) and also that the innovation and growth here unfortunately seems to have plateaued.
Types of Data
Public quant funds used the data exhaust of the traditional investors as their fuel to build incredibly successful funds. The data exhaust here is the time-series price fluctuation in security markets. Quant funds ran statistical models on these time-series data sets and identified repeatable statistical patterns that became the foundation of their fund.
So what is the data exhaust in venture? "Secondary" information about funding rounds: who the investors in the round were? Who was lead investor? Were they new investors or follow-on investors? What industry is the company in? How much VC funding has gone into this industry this year? Growth of VC funding in this industry this year? Number of VC deals in this industry? Location of startup? Schools of founders? Are they first time founders? etc. etc.
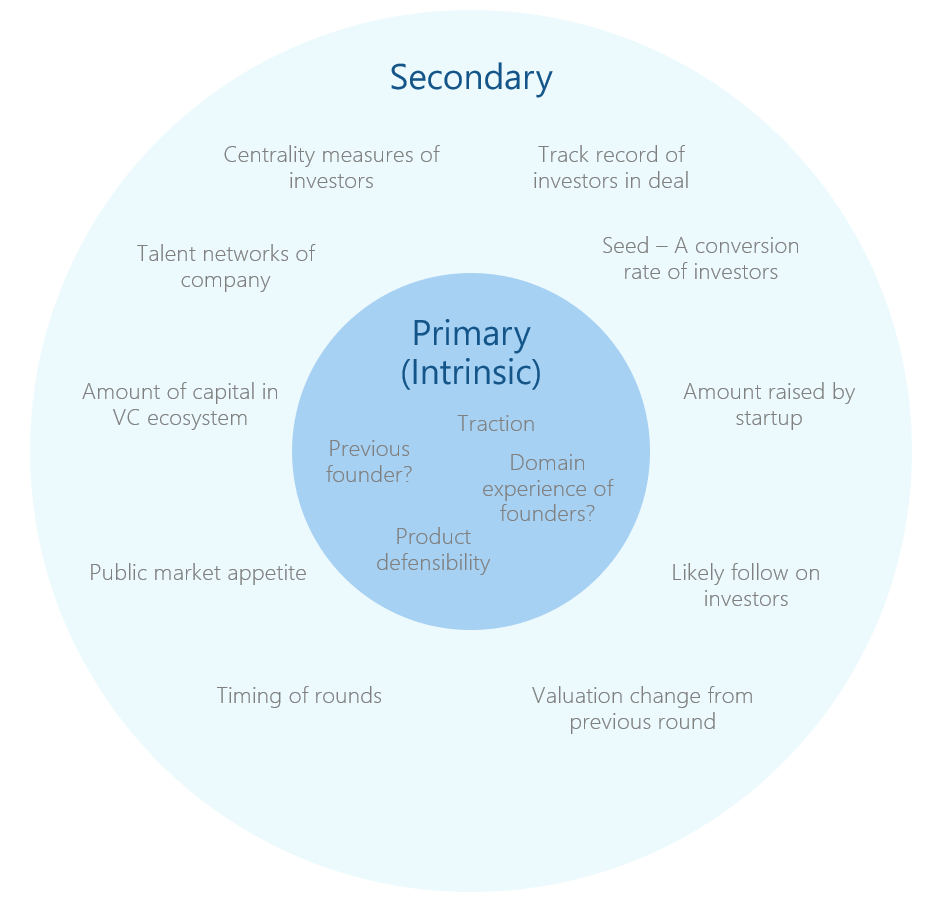
The above data can be ripped from Crunchbase, AngelList, PitchBook, CBInsights, LinkedIn, SEC EDGAR, PwC MoneyTree and many other creative sources.
Future Directions - Quantamental VC
“I believe the attempt to make a thinking machine will help us greatly in finding out how we think ourselves.”
Part of the benefit of examining the efficacy of quant approaches to VC (and indeed in building ML models to support VC investment decisions) is that it forces an examination of the way we currently understand the venture business. Here we've systematically analyzed the the architecture of the public and private markets which I think greatly helps to understand, in Turing's words "how we think ourselves."
Today, there is a question of how much data could/should be used in venture. In High Output Management, Andy Grove said "Anything that can be done, will be done, if not by you then by someone else." I believe leveraging data in the venture investment process can be done. Building a fully standalone quant fund may still be some years off. The reason for this I believe lies in the developing architecture of the private market. The 'electronification' of the public markets in the 80's greatly enhanced the ease with which quant strategies could be built and deployed in the public markets and we are seeing an equivalent "datafication" of the venture business today.
I believe the near future is quantamental VC funds. This is already starting to be realized; Sequoia has a data science group, Social Capital (had) a Head of Data Science and many other funds are not public with their data effort in the hopes of maintaining competitive advantage. The combination of the relentless growth of data available, the changing architecture of the early stage market, and the extreme need for differentiation given the explosion of funds, I believe will lead to inevitable innovation in the venture industry of the coming years.