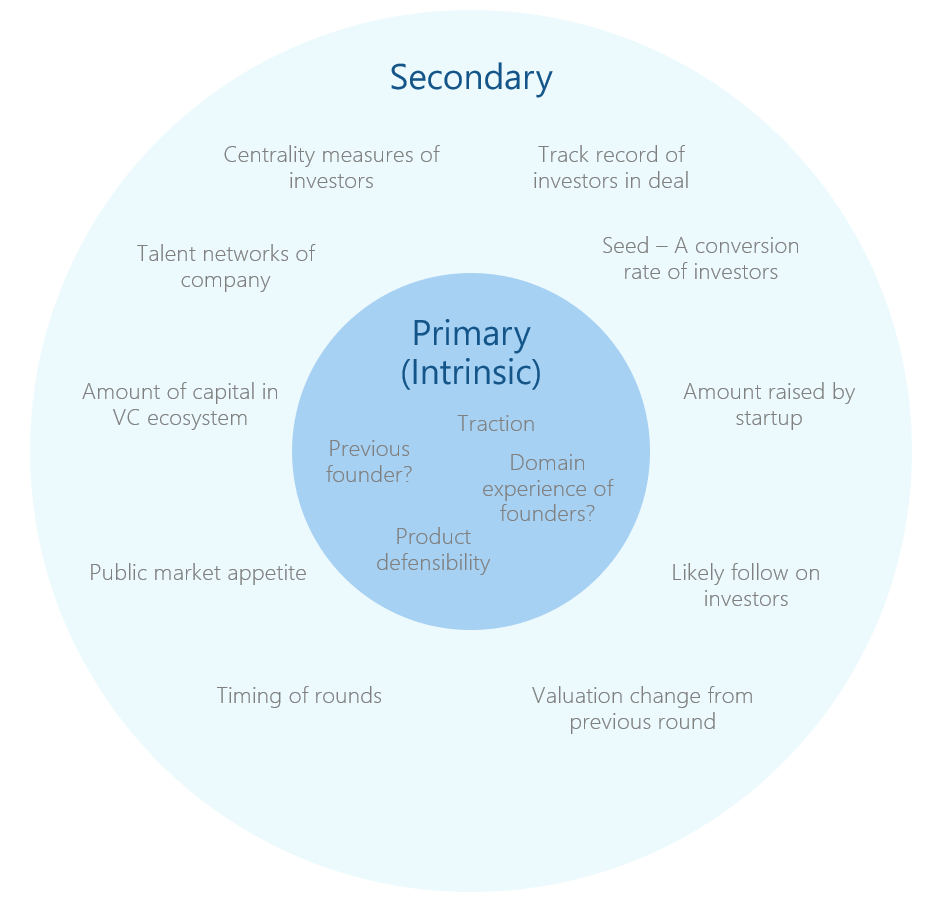
TL;DR: AI does not create a decentralized commons economy; it commoditizes production while recentralizing power in compute, shifting economic value toward distribution, trust, and uniquely human intent.
Intent is the scarce human capacity to choose goals and impose direction on infinite generative possibility. It is the act of mobilizing the machine’s attention—and your own—around that choice.
I’ve been revisiting Yochai Benkler’s The Wealth of Networks. Writing in 2006, Benkler argued that the "networked information economy" was shifting the means of production from industrial firms to "commons-based peer production." It was the era of Wikipedia and Linux and the belief that low-cost hardware plus human collaboration would break the monopoly of the firm.
But looking at the current state of agentic AI, Benkler’s thesis is being cannibalized. We are shifting from the social production of the network to the synthetic production. It is clear now that we have moved from the “networked information economy” to the “agentic economy”.
The Collapse of Cognitive Capital
Benkler’s core argument was that the physical means of production (the computer) were now in the hands of the individuals. But there was always a hidden "tax" on that production: the cost of expertise. You could own the "printing press" (the laptop+internet), but you still had to spend ten years learning how to be the writer, the editor, and the software engineer, the video editor.
AI is effectively commoditizing that expertise. We are moving toward a "Company of One" where the coordination costs Benkler discussed (friction of finding and managing collaborators) are dropping to zero because your "peers" are now a swarm of digital agents.
The Production Fallacy
When the cost of production goes to zero, the value of the product as a standalone asset also approaches zero. If every "Company of One" can vibe-code a sophisticated data pipeline over a weekend, then the code itself is no longer the moat. The bottleneck has shifted from Production to Distribution.
In a world where everyone owns the "means of production," the only thing left that is truly scarce is human attention. We are entering an era of infinite noise.
The Failure of the Peer-Review Filter
Benkler believed the 'Babel objection', that a world of total production would be a world of total noise, would be solved by peer-production. He thought we would filter each other. But he didn't account for a world where the noise is agentic. When the 'peers' doing the filtering are also AI, we risk entering a feedback loop where significance is lost in a self-referential cycle of synthetic content.
The Means of Inference
The "means of inference" are more centralized than ever.
We are in a weird paradox: an individual has more power than ever to create, but they are more dependent than ever on "compute landlords", the few entities capable of training and hosting the massive models that power these agents. Benkler’s dream of a "commons" is being replaced by a digital feudalism where we all own the hammer, but we have to rent the electricity and the nails from a handful of mega-firms.
Furthermore, firms don't just exist to manage transaction costs (as Coase and Benkler argued); they exist to manage liability and trust. You can code a medical agent in your basement, but you can’t provide the regulatory "shield" or the brand-equity trust required to make a patient use it.
The parallel to my earlier thoughts on "shared worlds of significance" is clear. When everyone possesses the means to code up everything, the value shifts upstream to intent. The winners won't be the best "producers"; they will be the ones who can navigate the "compute landlord" reality while maintaining a unique human signal in a sea of synthetic noise.
It’s happened before, with the press, with the web, but there is nothing to compare it to now. The past is an irrelevant prior. We’re forking into a new reality where the "means of production" is simply the courage to have an idea and the distribution strategy to make it matter.